How Video Formats Work
January 31, 2018 by

Introduction
In my presentation on GIFs, I focused on how GIFs work and how GIFs compare to modern image formats. Let’s look a bit at modern video formats and see how they compress data.
Here at GIPHY, we obviously work a lot with the GIF format, but you might be surprised to learn that we also work a lot with video. Much of our incoming content is video, and we often display and deliver video rather than GIFs because modern video formats both look and compress better than GIFs.
But modern video formats are complex beasts: more complex than GIFs. To understand them, we need to think about color formats, chroma subsampling, resolutions, container formats and codecs. I’m assuming you are already familiar with basics like resolution and frame rates, but let’s break down the rest.

Color Format and Chroma Subsampling
Many developers are used to thinking about color in terms of red, green and blue, or RGB. These are the colors we use for display, when defining web colors, and often when working with raw pixel data. You might also be familiar with HSB, CMYK, or other “color spaces” used in programs like Photoshop, but you are probably less familiar with the colorspace used natively in most video formats: YUV (Footnote: For the purposes of this post, we are making some generalizations about color spaces. You might hear about other color spaces in the same family as YUV that have other names like Y’UV, YCbCr and so on. These are different, but since they belong to the same family, we’ll treat them as one).
Historically, YUV’s advantage was the ability to add color to black and white television broadcasts without interfering with existing signals or adding unnecessary information. While this kind of compatibility is not needed in the digital age, YUV still has a major advantage over other color spaces: this color space separates luminance (which can be thought of as brightness) from chrominance (which can be thought of as color), so we can apply different levels of compression to brightness and color. This separation is convenient because color is less significant to our perception of image quality than brightness.. By reducing the resolution of the chroma components relative to the luminance components, we can significantly reduce the bandwidth requirements of the video with almost no visual impact. This is called “chroma subsampling”, and is indicated using 4:X:Y notation. For example, 4:2:0 video has half the chroma resolution in both the horizontal and vertical direction, and is extremely common in consumer formats, such as Blu-ray. 4:4:4 video, on the other hand, uses no chroma subsampling, and is usually considered overkill, even for professional video.
Codecs
Once the color is converted to YUV and subsampled as required, the video can be further compressed using any number of available codecs, such as H.264, VP8, Sorensen and Cinepak. Despite the wide variety, the codecs have much in common and it is possible to make some broad generalizations.
Like image compression formats, modern video formats can compress spatially, meaning pixels can use information from their neighbors to reduce storage requirements. However, they can also compress temporally, which means that frames can use information from nearby frames to reduce storage requirements. To enable temporal compression, individual frames can be divided into three categories:
- – Intra-Frames, or I-Frames, contain a complete image. Because of this, they are not dependent on adjacent frames for display, and do not enable temporal compression. I-Frames are sometimes called “key frames.”
- – Predicted-Frames, or P-Frames, are dependent only on previous frames for display.
- – Bidirectional-Frames, or B-Frames, are are dependent on both prior and subsequent frames for display.
Complicating the matter is the fact that some modern codecs allow frames to be broken up into “macroblocks” or “slices”, which can be individually treated as intra, predicted, or bidirectional. Any given frame can be divided into rectangular regions, and those regions can be treated as separate types of frames.
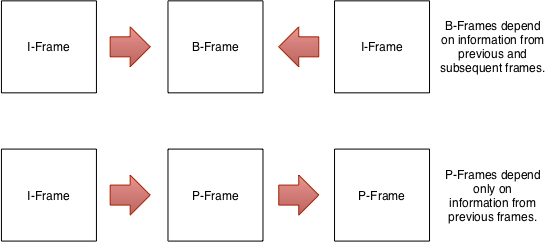
Obviously B-Frames allow for the most compression, but they can be complex to encode and decode. On the other hand, I-Frames allow for the least compression, but are easy to encode and decode. Because I-Frames can be rendered without reference to other frames, they represent points in playback that don’t require any buffering. As a result, I-Frames play an important role in “scrubbing,” skipping, video editing, streaming, and ensuring consistent picture quality.
A set of images bounded by I-Frames is sometimes called a “Group of Pictures” or GOP. A GOP can be thought of as an atomic unit: it can be operated on and transmitted independently, without reference to other video content. GOPs therefore play an important role in streaming, where videos need to be broken into pieces for efficient delivery, and encoding, where videos need to be broken into pieces for parallel processing.
Container Formats
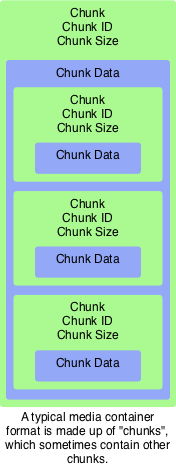
Once compressed, video must be stored in a “container”, such as OGG, AVI, FLV, MP4, MPEG, QuickTime, WebM , etc. Containers can be thought of as the box that the encoded data goes in. A physical box might have a shipping label with information about what’s inside, and might contain one or more items within. Similarly, video containers store metadata, ranging from information about the codec itself, to copyright and subtitle information. They also allow multiple video and audio streams to be packaged in one file.
Most container formats are organized into “blocks” or “chunks.” These blocks allow readers to skip over sections they are unable to read or not interested in. Of course, readers that are unable to read certain chunks may render the video incorrectly, but in principle this design allows for formats to be extensible, and for readers of different types to gather the minimum amount of information they need as easily as possible.
Of course, not every container format works like this. Some formats, especially old audio formats, are simply divided into metadata and data. But as requirements for things like interleaving data and extensibility have increased, newer formats are usually more complex. Some formats, like the MPEG Transport stream, include error correction and synchronization, which might be useful over unreliable transports, but usually just add overhead when sent over TCP/IP.
Putting it All Back Together
So far, we’ve discussed the particulars of video formats in the order you might need to think about them for encoding. To decode a file, you need to think about things in the opposite order: first you need to read the container format, then read the codec, and finally convert the (usually) YUV data to RGB for display, taking chroma subsampling into account. Because some of the steps involved are lossy, you might not get back exactly what you started with, but for most modern codecs, the goal is for the result to be as close to the original as possible.
-Bjorn Roche, Sr. Media Pipeline Engineer