GIPHY’s AI Can Identify Lil’ Yachty, Can Yours?
March 5, 2019 by

GIPHY is excited to announce the public availability of our custom machine learning model, The GIPHY Celebrity Detector, which is able to discern over 2,300 celebrity faces with 98% accuracy. The model was trained to identify the most popular celebs on GIPHY, and can identify and make predictions for multiple faces across a sequence of images, like GIFs and videos.
This project was developed by the GIPHY R&D team with the goal to build a deep learning model able to annotate our most popular content at a level equal to (and ideally better than) similar fee-based models and services offered by major tech companies. We’re extremely proud of our results, and have released our model and supporting code with the hope others will build off our work, integrate the model into their own projects, and perhaps even learn from our approach.
The model and code is available for download via GIPHY’s Github page.
Motivation
Entertainment and popular culture are at the heart of GIPHY. Half of all the search queries we get are entertainment related. Aside from cute animals, GIFs featuring celebrities drive more traffic across our API integrations, website, and mobile apps than any other type of content. Take a look at our top GIFs from 2018 and you’ll see a number of famous faces represented, like Cardi B, whose “okurrrrr” GIF has accumulated nearly 400 million views. Likewise, GIPHY Studios regularly collaborates with celebrities to create original content, like stickers, reactions, and even ads, as with our work creating gifs to promote the film “Sorry to Bother You.”
(Promotional gif for “Sorry to Bother You”)
We needed a tool that could find and annotate this content within our ever-growing library of GIFs, so that this content could then be found in our search engine. Between our existing GIF library and the celebrity-based content we generate internally, we knew we’d have abundant training data from which to pull. Having total control of the model lets us update it as needed to maintain GIPHY’s unique position at the cutting-edge of popular culture.
(GIPHY’s AI can identify Lil’ Yachty, can yours?)
Model Training
To generate our training data, we extracted all the celebrity names from the top 50,000 searches across all our platforms, including our website, mobile apps and integrations likes Facebook, Twitter, and Slack. This yielded a data set comprised of over 2,300 celebrity names (you can see the complete list here). While we had a good amount of labeled training data already, we also needed to scour the internet for supplemental images for names which had a smaller representation in our catalog.
The resulting dataset gave us lots of positive, representative images for the most-popular celebs, but the image sets we had for less-famous celebrities had more false-positives; as such, they were noisier. In order to refine these noisier sets, we used a separate model able to group images by similarity of facial features to evaluate the overall uniformity of each dataset. Clean datasets had smooth distributions, whereas noisy datasets were more unevenly distributed and clumpy. Those clumps in our noisy datasets that contained the most images tended to have similar distributions as our clean datasets, indicating those groupings were positive images of the celeb and could be safely used in training. This process helped us to de-noise and improve the accuracy of our model considerably.
Celebrity Detection
The celeb-detection process itself consists of two parts: face detection and face recognition. When a GIF or image is submitted to the classifier, it attempts to detect all faces across all frames using a popular pre-trained model called MTCNN. Each face is then sent through a deep convolutional neural network, based on Resnet-50 and trained on the dataset mentioned above, for recognition. The network itself is a facial features extractor which constructs a vector space of faces grouped together using center loss. Each face processed by the network is given a celebrity prediction along with a unique feature vector.
Once all faces have received a prediction and vector set, as a post-processing step we use a GMM algorithm in a supervised fashion to cluster each face by its vector representation. For each cluster, an aggregate prediction is computed for all the faces within the cluster yielding one or more celebrity names, each with a confidence score. The model’s final output is the combination of these predictions across all clusters.
Model Validation
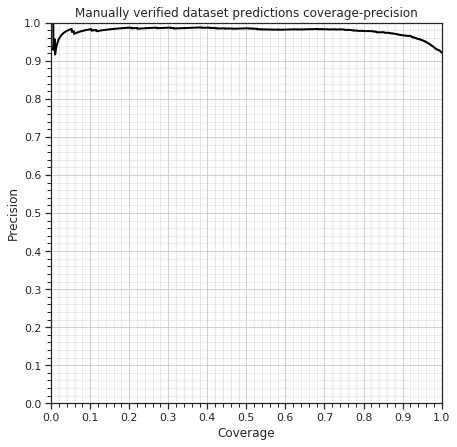
We took two approaches to model validation. First, we used the Labeled Faces in the Wild test. Our classifier scored a 96.8% accuracy. Then, we crowdsourced a labeled and verified a validation dataset consisting of almost 1000 popular GIPHY celebs. The model achieved 98% precision for 75% coverage on this validation dataset. Here is a coverage-precision curve for the results:
Over the next few months we’ll be providing more details on this project here on the GIPHY Engineering blog, including a technical deep-dive and an overview of how we tested the model for different types of bias. Until then, we encourage you to download and play with the model and let us know if you come up with any cool use cases or extend the model’s capabilities for your own needs.
– Nick Hasty, Director of R&D
GIPHY R&D Team
– Nick Hasty
– Ihor Kroosh
– Dmitry Voitekh
– Dmytro Korduban