Part 1: Computer Vision @ GIPHY: How we Created an AutoTagging Model Using Deep Learning
December 3, 2020 by

Motivation
GIPHY search is powered by ElasticSearch, where GIFs are represented as documents with various features, such as tags and captions. Tags in particular have a great impact on the search performance. Therefore, at GIPHY Engineering, we continuously track and improve their quality with both manual and automated verification.
However, for the last couple of years, the number of GIFs in our library and size of search query space has grown dramatically, making feature maintenance difficult. Since tags are added manually by users who upload GIFs, a portion of the GIPHY catalog is missing relevant tags. Missing tags happen when the user uploading the GIF fails to add tags, assigns tags that are too general, or assigns irrelevant tags. Without tags, this content is unlikely to surface as a result of relevant search queries, depriving creators of well-deserved attention and making some of GIPHY’s search results less complete than they could be.
Our approach to alleviating this problem was to create a deep learning model able to predict tags for a GIF, and to present these predicted tags to our users so they can make the final judgement about which tags to include. The goal for the model is to increase the discoverability of our users’ content. Consequently, the tags we predict need to be both relevant and reflect our most popular search queries so that their GIFs might show up in results for those searches. We call this model the AutoTagging Model, and in this two-part blog post, we’ll break down the whole process of its creation, from training, to deployment.

Selecting a Base Model
Considering the abundance of open-source, performant Computer Vision models, we decided to leverage a pre-trained solution which could be fine-tuned on the GIPHY dataset. Even though existing models are designed to predict labels for a single image, they can be extended to make predictions for an entire GIF by sampling a fixed number of frames and aggregating these frame-based outputs into a single output, either by applying average pooling or learnable pooling (MLP, CNN, RNN, Transformers). We’ll cover our architectural solution in the next sections.
We started with a torchvision package that provides a variety of models pre-trained on Imagenet dataset, from tiny and less accurate (MobileNet V2) to massive and performant (ResNext and NasNet).

As an alternative, we followed public, open-source research done by Facebook’s AI Team which showcases that by utilizing a huge amount of data with weak supervision (in this case – IG videos and images with noisy hashtags added by authors) in combination with clean labeled data (e.g. Imagenet) we can get an even more accurate model. This can be achieved by using a Teacher-Student training setup. A Teacher model is pre-trained on a weakly supervised dataset, and fine-tuned on a clean dataset. After that, a Student model is pre-trained on a weakly supervised dataset automatically labeled by a Teacher model and fine-tuned on a clean dataset.
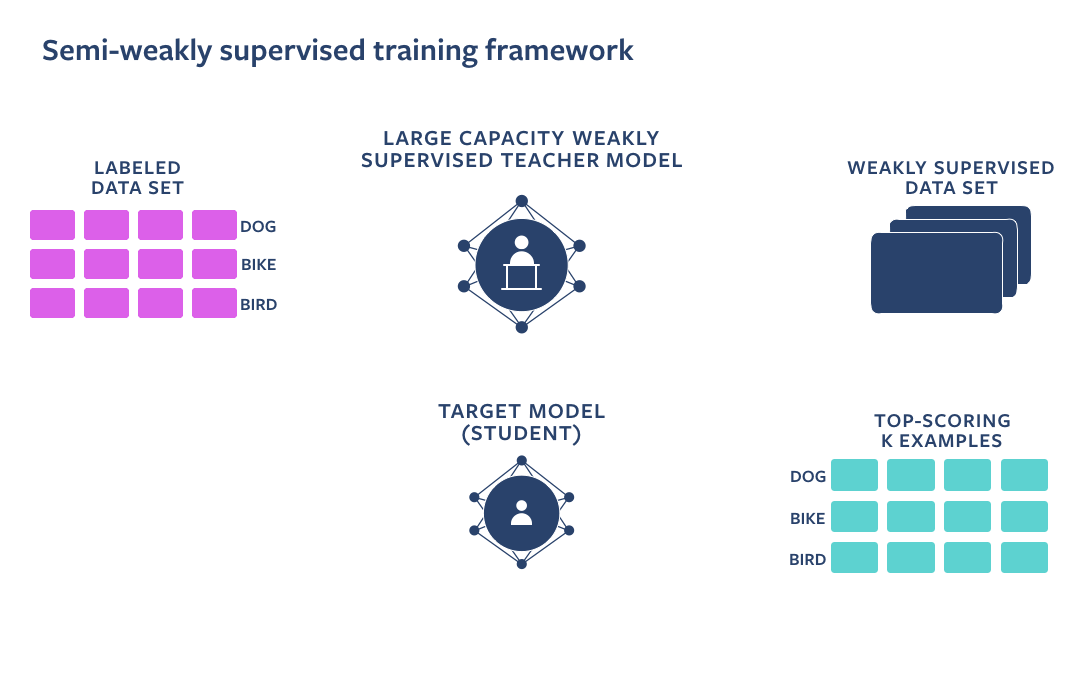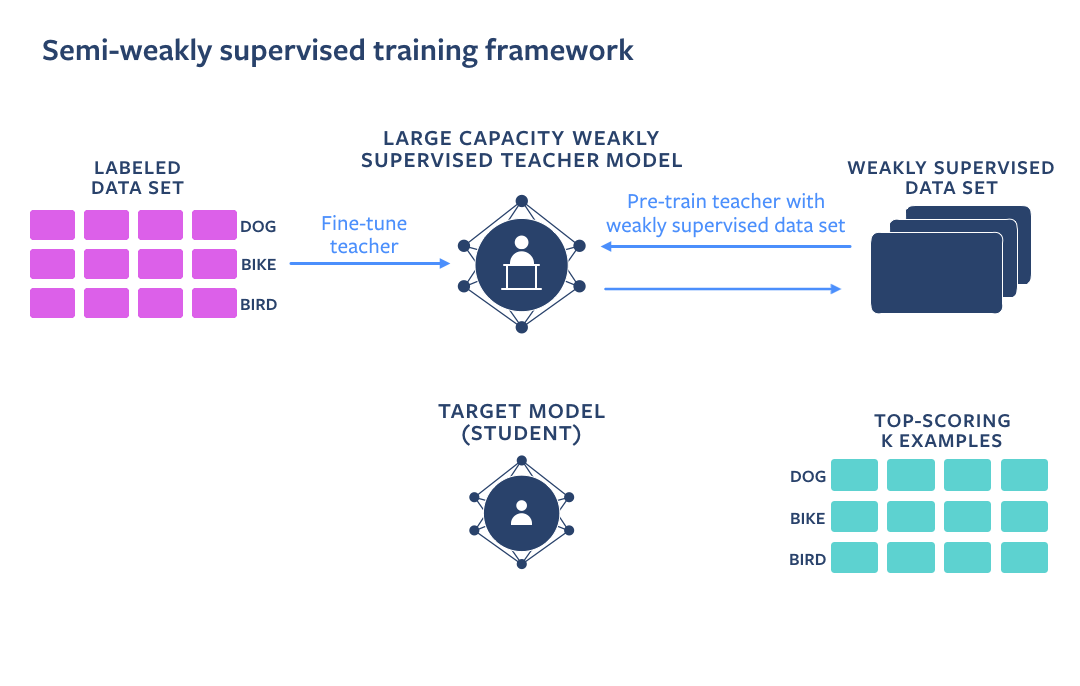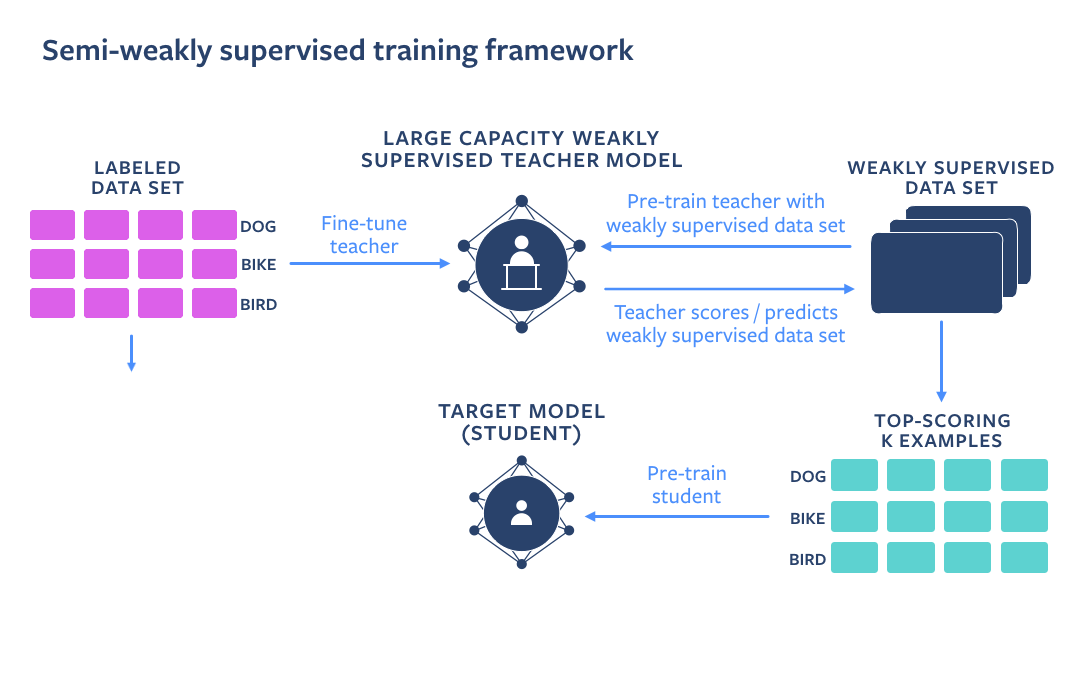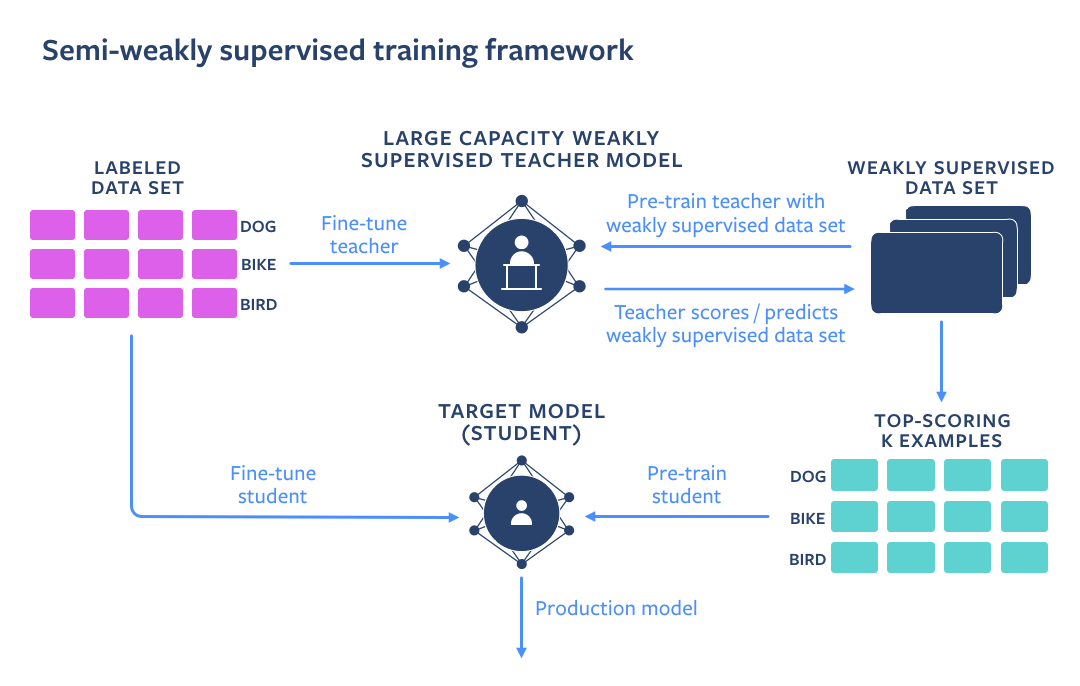
Facebook evaluated these models on public benchmarks (Kinetics, Imagenet) and proved that this training approach significantly improves accuracy compared to more straightforward strategies.

Facebook AI’s WSL models are available via torchhub. We tested both video and image-based models (aggregation is done via average pooling) on our GIFs and couldn’t observe any substantial difference in results subjectively and on our mini benchmark. Moreover, a video model is much slower in both training and inference procedures. Therefore, we decided to limit our further experiments to a model trained on images.

In summary, we kept two options for the base learner: pre-trained models from torchvision (Imagenet) and FB WSL (Instagram + Imagenet).
Labels Engineering
In the case of FB WSL, pure Imagenet labels were used and extremely diverse Instagram hashtags were projected onto this set of 1K general labels. We can’t follow the same track since we’re not trying to beat any benchmarks: our goal is to build a model that will speak in GIPHY-specific vernacular. In other words, we do not need narrow labels from Imagenet, like “cuirass”, but instead we need popular terms describing general emotions, reactions and other adjectives, such as “happy”, “mic drop”, and “thumbs up.” Also, we don’t want our labels to be too specific assuming chances of failure are considerably high (e.g. classifying a particular celebrity or movie). Apart from that, our tag set should be clean (no misspellings, synonyms, etc) and compact (up to 2-3K labels because of computational reasons).
To collect such a set, we started with a complete list of all GIPHY tags and applied various transformations and filtering procedures to obtain our final refined set:
→ Used our own custom Language Detection Service to leave only English tags
→ Applied deduplication (removed misspellings, prefixes etc)
→ Removal of people and movie-related tags via Google Knowledge Graph
→ Grouping of remaining terms based on lemmatization, stemming, and clustering via domestic semantic tag space
→ Each cluster is represented by a most common tag
As a result, we obtained around 2K tags. This set was manually verified and enriched by our editors with missing popular GIPHY terms leading to approximately 2.5k labels in total.
GIFs Dataset
To compile our dataset, we collected about 6M of GIPHY’s most popular GIFs and their tags, and then discarded GIFs that were too short or too long. For each GIF, we kept a maximum of 16 frames. We then reduced our initial dataset by only using GIFs that had at least one of the tags from our label set, which left us with a dataset of approximately 3M of GIFs. In order to track performance of models during training, we created a validation dataset based on GIFs with “editorial tags”–tags that were added by GIPHY’s in-house editors–as opposed to tags added by GIPHY users. Our editorial tags are cleaner and more accurate, so metrics measurement on this dataset is more trustworthy than on the random hold-out split or cross-validation. This set includes around 200K GIFs, which are excluded from the training dataset. For the test dataset, we have a small subset of validation dataset that was manually reviewed.
Since our dataset is highly imbalanced (see a below diagram), we created a custom training data loader that performs stratified sampling of GIFs on every epoch to ensure even distribution of samples per class. The problem of low-frequency classes is addressed via various augmentations applied for input frames. Since the majority of GIFs have more than one tag, we treated this task as a multi-label classification problem. Therefore, our training sample is an (X, Y) pair, where X = GIF frame and Y = the list of correct labels with confidences.
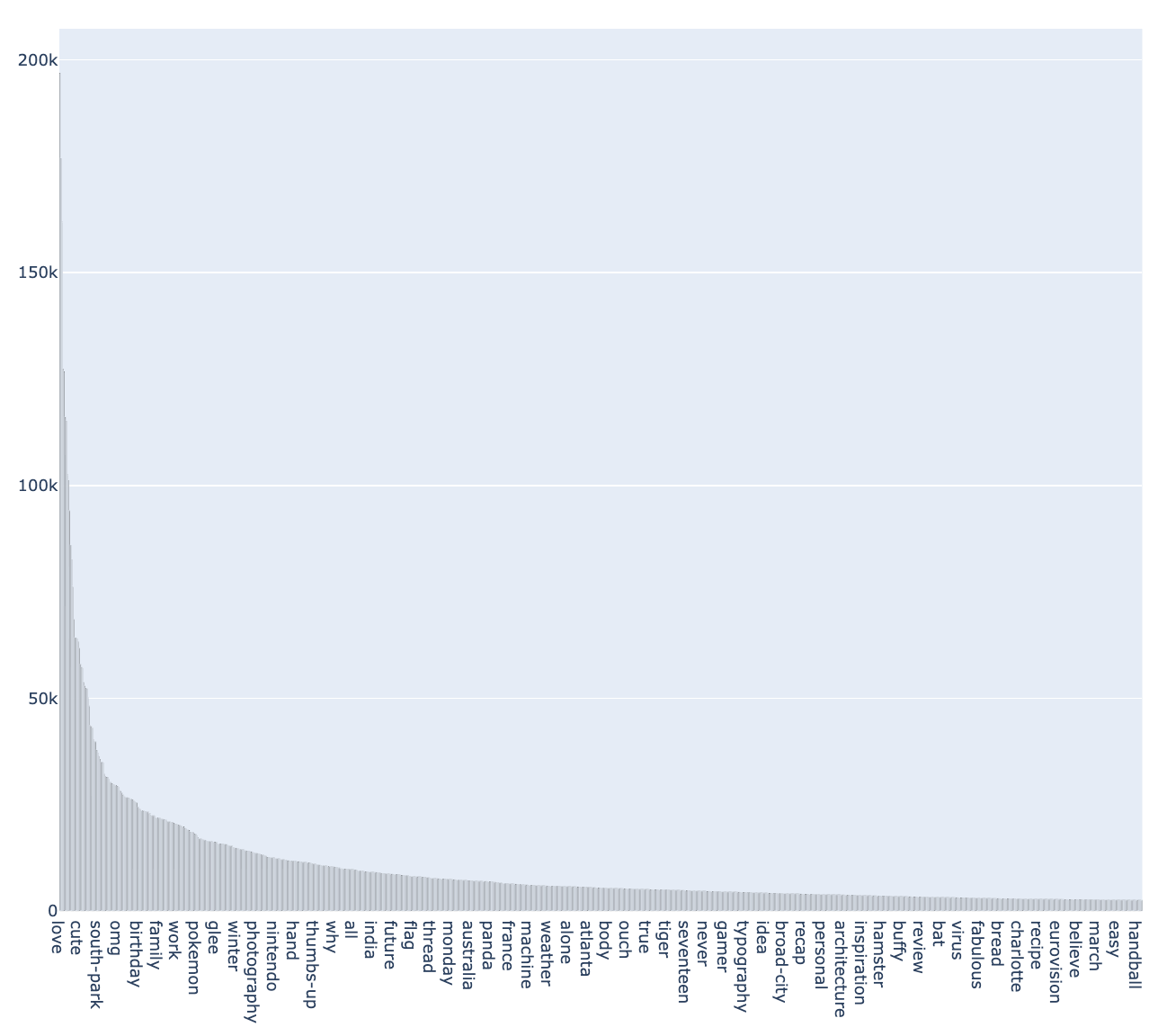
From the very first experiments we could see substantial downsides of annotations in our original training dataset: many GIFS lacked relevant tags while others had irrelevant tags. A small percentage of such content is enough to negatively influence the training, so we performed some automatic enrichment and adjustments of labels by applying an approach we call the “Experts Voting.”
“Experts Voting” Dataset
To create this automated pipeline for dataset generation, we collected vector representations for GIFs from various sources:
→ ResNet50 Imagenet embeddings
→ Internal semantic model for GIFs representations
→ OpenGPT2 representations of OCR results
These representations and corresponding original tags are used to create kNN classifiers separately for each modality (based on NMSLIB library). This simple model allows us to leverage similarity measures in those embedding spaces of GIFs to infer GIF’s tags by looking into the tags of its neighbours.
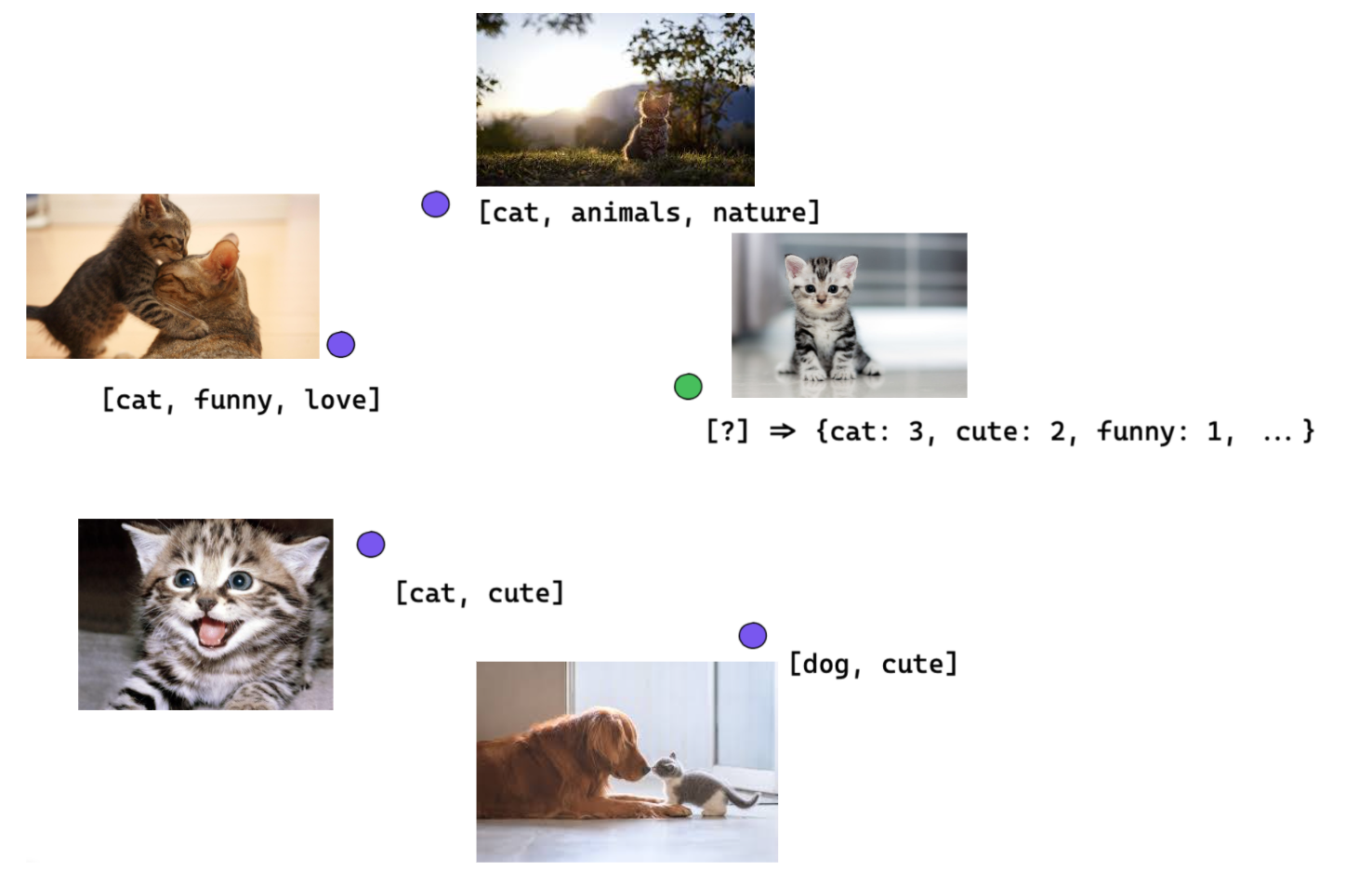
After these models are built we can get the top 10 closest GIFs for each given GIF from each of those models and then compute frequencies for their tags (e.g. tag “cat” appeared in nearest GIFs from the Imagenet model 3 times and 2 times in GIFs for TRN MIT model, therefore the final frequency is 5). Then, in order to give more trust to models that provide more accurate predictions, we adjust our frequencies by multiplying them by weights calculated for each model – the percentage of GIFs for which each model correctly predicted at least 1 tag from a GIF.
| Model | Weights |
|---|---|
| Semantic Model vectors | .54 |
| Imagenet vectors | .33 |
| MIT vectors | .28 |
| OCR vectors | .2 |
After that, modified frequencies are filtered out by a static lower bound to limit the amount of noise and normalized from 0 to 1 to match confidence values in our training dataset. This allows us to significantly extend our training dataset (almost to the size of the full collection of GIFs that we initially processed – 6M) with GIFs with reasonably confident tags. Apart from that, using these models’ results we are (to some extent) able to fix original GIPHY tags in the following way: if a given original tag was present in at least one model’s prediction for a given GIF, we leave it confidence of 1, if it was not – we reduce the initial confidence to 0.7. This processing doesn’t affect validation and test sets as we wanted to keep the original tags intact.

Stay tuned for our second post where we’ll dive into our experimentation environment, training and evaluation, and finally, deployment.
— Dmitry Voitekh, AutoTagging Tech Lead
Additionally, many thanks to Proxet and their engineers for their valuable contributions to the project!
GIPHY Engineering Signals Team
— Nick Hasty, Team Lead
— Dmitry Voitekh
— Ihor Kroosh
— Taras Schevchenko
— Vlad Rudenko