Scaling Redshift without Scaling Costs
March 6, 2018 by

Drowning in Data
Interactions with GIPHY via our apps and API network are generating 3+ billion events a day. Over the years we’ve built and maintained infrastructure to process and analyze all this data to improve our search algorithm, power our view counts, identify cultural trends, and much more. Today we rely on a combination of tools like Kinesis and Spark to move and transform data.
Like many organizations, we use Amazon’s Redshift to handle much of our data warehousing (we use BigQuery too, but that’s another story). Redshift is a distributed columnar database. Similar to EC2 instances, Redshift is billed on a per instance, per hour basis. Amazon offers two instance types, Compute (DC2) and Storage (DS2). The former is optimized for query performance, and the latter for data storage. The size, and therefore cost, of a Redshift cluster depends on how much data we have and whether or not we are willing to sacrifice a bit of performance to achieve extra storage.
With the amount of data we are consuming, we realized that the costs of analyzing it was increasing every month. As we add more data at an accelerating rate, we scale our cluster up to keep pace with storage. Many organizations circumvent this by not storing historical data in Redshift. However, the nature of our business necessitates easy, interactive access to historical data. Understanding what is going to be the best Valentine’s Day GIF requires looking at past Valentine’s Days and identifying patterns. The ease of data access allows our lean team to service the needs of our hundreds of millions of users at scale, while not increasing our infrastructure costs at the same rate. While GIPHY is by no means un-resourced, this efficiency is important to our overall structure. The ease of data access allows our lean team to service the needs of our hundreds of millions of users at scale, while not increasing our infrastructure costs at the same rate. This efficiency is critical to our ability to iterate.
Endless Tuning
Beyond costs, our team invests a lot of manpower in running Redshift optimally. Tons of blog posts, Stack Exchange answers, and Quora posts break down all the ways to tune and optimize Redshift. Still, it seems like there are a billion settings to tune, and always a new one to learn. For example, should I use DIST_ALL for my dist key? When is it better to use a COMPOUND sort key vs INTERLEAVED? Don’t forget to vacuum your tables, but the right cadence and schedule is needed because you can only vacuum one table at a time, and the entire cluster takes a performance hit! I’d be doing you a disservice if I didn’t remind you to analyze your tables, too. What happens when you eventually need a bigger cluster? Resizing a Redshift cluster makes it Read-Only, and in some cases can take hours. Scheduling and coordinating a time to potentially not have fresh data for the entire company is far from ideal at GIPHY’s scale.
Redshift Spectrum
As with all our architecture, be it K8s or Redshift, we’d like to stop scaling our costs linearly, and make our data warehouse less complex to manage. In this case, we’ve found a solution in Redshift Spectrum. Announced in April 2017, Redshift Spectrum is a feature that allows Redshift to query data that does not live in the cluster, but rather on S3.

Spectrum is seemingly a sibling to Amazon’s Athena product. Both are fully managed solutions based on Presto allowing for distributed SQL run against S3. They both cost around $5 per terabyte scanned,a similar cost and model to Google’s BigQuery. With Spectrum, our largest event tables can live on S3 rather than being distributed on the disks of the cluster itself. S3 becomes our data lake and Redshift remains our data warehouse. When we initiate a query requiring data on S3, Amazon elastically scales out resources for the query and we pay only for the amount of data accessed. Given the vast majority of our queries happen during work hours, and few are full table scans, we end up saving more money by paying for these on-demand queries than we would running multiple instances 24/7.
Building Things is Hard
The key to minimizing our costs with Spectrum is reducing the amount of data we need to read in order to perform a query. Our first step to achieving this was denormalizing our events to include the values we commonly group against.. Spectrum can also use the folder structure of S3 as an index. If wanted to make querying by day easy, we could sort all our data into folders in our bucket with names like date=2018-01-01 and Spectrum could use the folder metadata to pick only the folders needed based on the SQL call. By nesting folders, we can essentially mimic a B+ tree index, similar to what is found in most row-oriented RDBMS. Each folder we set up contains a very small amount of data, minimizing the amount of data Spectrum actually read at query time.We came up with a complex folder structure, with millions of nested folders.
While an interesting idea in theory, we discovered three problems. First, we ran into rate limiting issues trying to quickly create so many files and buckets in S3 from Spark. We thought about contacting AWS to get around this, but ultimately the overhead of writing so many files was making our Spark jobs too slow for feasibility. We also discovered Spectrum’s overhead for analyzing the tree of folders in a bucket; we lost performance from having too many. Lastly we discovered that there was a decent bit of latency from Spectrum in the following areas:
- 1. Parsing our data from text formats on S3
- 2. Filtering & aggregating the data
- 3. Transfering to our Redshift cluster
Parquet
We were able to solve all of these problems by storing all our data in Parquet format. Parquet is a binary, column oriented, data storage format made with distributed data processing in mind. We have been using Parquet for a long time in other parts of our data infrastructure due to great interoperability with Spark.
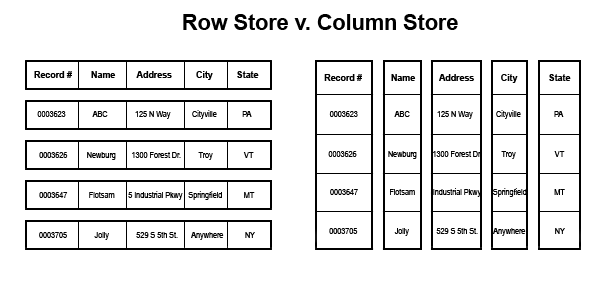
Parquet can be slower to write than CSV or JSON but it is substantially faster to read thanks to a reduced serialization cost and column-oriented efficiencies. To find the sum of all clicks in a day, a system only has to read the parts of the Parquet file that has that column, not the rest of the data in the file. This is both faster and saves us money on Spectrum costs. Additionally, each Parquet file has metadata detailing the range of values that can be found inside. We can take advantage of this by writing spark like the following:
scala
df.repartition($"date")
.sortWithinPartitions($"country", $"content_id")
.write.partionBy("date")
.parquet("s3://")
I won’t get into the weeds of the above, but essentially we can tell Spark to write Parquet files to the bucket where we sort all the files into folders based on the day (partitionBy). Within each of these folders, we have a number of Parquet part files. Each part file has its columns sorted by country and content_id. If we run the following query in Spectrum:
sql SELECT sum(clicks) from click_events WHERE date = '2018-01-01' and country='US'
First, Spectrum can quickly navigate through the directory structure in our bucket to find the date=2018-01-01 folder. Then it can read the metadata in each Parquet file, noting which files have a max min country range that US would fall into. By using sortingWithinPartitions in Spark, we ensured this metadata will be present in each part file. Because these files are independent, Spectrum can parallelize the metadata inspection, yielding even better performance.
The sums can also be parallelized. Each Spectrum process/worker only needs to sum all the clicks found in the files it has identified as valid. All the click numbers will be on disk together, because of columnar storage, so the worker can just sequentially scan on the disk and sum what it reads. Spectrum can sum all the intermediate sums from each worker and send that back to Redshift for any further processing in the query plan.
Conclusions
Overall the combination of Parquet and Redshift Spectrum has given us a very robust and affordable data warehouse.
Pros
- – No Vacuuming and Analyzing S3 based Spectrum tables
- – Diminishing Marginal Costs
- – We can still write to S3, even during a cluster resize
- – Can utilize features like S3 glacier and versioning for more robust data backup and restore
Cons
- – There is additionally latency added by Spectrum queries
- – We have to be careful to avoid full table scans
- – When doing joins the Query planner will try to move all the S3 data to the redshift cluster and do the join there, this eliminates most of the performance gain of this setup
- – We can’t change the schema. Spectrum doesn’t have the mergeSchema ability that spark does so creating a new schema means creating a new table and using a view to union them.
— Niger Little-Poole, Data Scientist