Pupline: GIPHY’s Media Metadata Pipeline
October 29, 2019 by

Here at GIPHY, we receive thousands of GIF uploads each day. Like any tech company, we love data: we want to attach as much data as we can to these GIFs so that we can improve their search performance and the user experience. We also want to do so in an organized, centralized, and asynchronous way so that we can collect the content data quickly and easily after the upload is completed. For example, we run our GIFs through Google Cloud Vision in order to get a variety of object detection data, and run everything through our moderation platform (more on that later). To do all of this, and more, we built Pupline. Pupline allows us to observe each and every GIF in our library and quickly write scalable jobs for analyzing or processing GIFs immediately after they are ingested.

Pupline has a simple, straightforward interface which makes writing a custom task to perform almost any image or metadata processing as simple as writing a Python function and deploying the changes. As a result, our team can quickly add new processing for GIFs as needed and other engineering teams can submit pull requests (PRs) to our codebase with minimal guidance from our team.
Celery

At its core, Pupline uses Celery to schedule custom tasks. Celery is a task queue framework, written in Python, which offers a powerful yet simple system for asynchronous task scheduling right out of the box, with minimal configuration. Celery tasks are run by workers, which listen on one of a number of supported message brokers (in our case, Redis). Workers monitor the broker for Celery messages (which can be generated by any application which follows the protocol) and, when they receive one, invoke the appropriate function with the arguments passed.
If both your tasks and your scheduling application are written in Python, task invocation is a breeze: simply write your tasks as functions, add one of a few Celery decorators, import your task functions into your application, and voila — you can now invoke your tasks directly from your application without writing any worker code. In fact, your worker and application tasks can be deployed using the same docker image! This means that you can spend most of your time writing business logic, and much less time worrying about scheduling and infrastructure because Celery handles most of that.
Infrastructure:
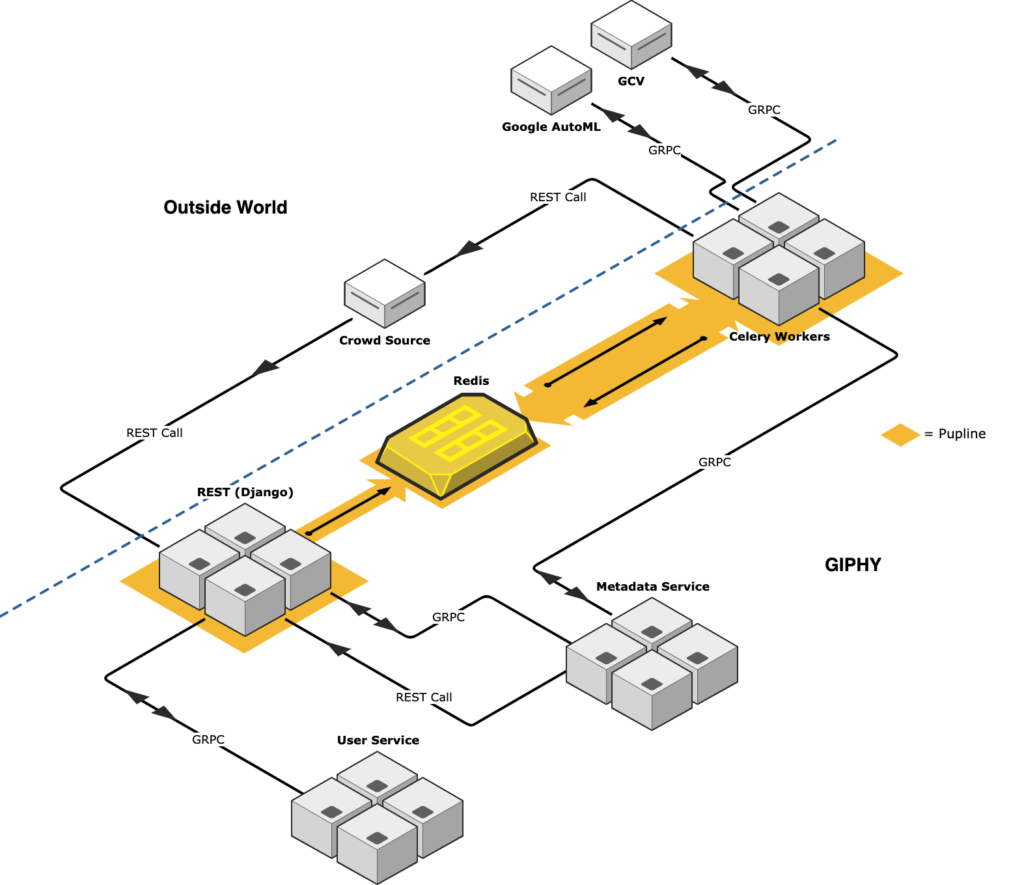
Our infrastructure is fairly typical of a Celery application. As our task scheduler, we use a Django application. This application exposes a few different endpoints for invoking the various processing pipelines that we’ve written for GIFs. Once one of the endpoints has been called (usually with nothing more than a single identifier indicating which GIF to operate on), Pupline collects various other pieces of information, such as user information and metadata, and sends task messages to Redis. Finally, the workers pick up task messages and invoke the relevant functions.
Batched Uploading
In our standard workflow, GIFs are passed to Pupline as soon as they are uploaded and tasks start running almost immediately. However, sometimes we identify large batches of GIFs that we would like to do additional processing on. While it is easy to pass huge batches of data to the Celery queue (as it’s backed by Redis, the only limit is the disk size) this can cause a problem; GIFs that are freshly uploaded will get stuck waiting for all of the jobs in the batch to finish before they can start. Since managing new GIF uploads is a high priority, we want to make sure that they are always processed before batch jobs.
To solve this, we implemented priority queues in Pupline. Dedicated workers scan the high priority queue exclusively, and any GIFs that require immediate processing, such as freshly uploaded GIFs, are sent to that queue. Whenever we wish to operate on a batch of GIFs, we add them to the low priority queue, and they are processed by batch processing workers.
What do we use it for?
Pupline is an ongoing project, and one of the great features of this tool is that it is very easily extendable by engineers. As a result, we can often use it to write quick, one off jobs that let us do GIF processing on the fly as needed. In addition, engineering teams around GIPHY are in the process of writing tools in Pupline to take advantage of its features.
Today, Pupline runs on every GIF uploaded to the platform, and performs a few important tasks to keep our content safe, relevant, and useful.
Moderation

One of the primary tasks that Pupline was built for is content moderation. Here at GIPHY, we take content moderation very seriously, and our moderation pipelines can be pretty complex. Furthermore, new moderation jobs can suddenly be required and we want to be able to quickly and safely provide the most in-demand content.
When GIFs are uploaded to GIPHY, they are first sent to our third party crowdsourcing provider for basic content evaluation. This provider allows us to run Human-in-the-loop (HITL) jobs on GIFs – these jobs allow automated pipelines to deliver content to trained participants who can classify and understand the context of GIFs much better than a computer can. After that, GIFs are separated into different content types and passed to various pipelines for further moderation steps.
Whenever we want to create or modify a job like this, we write a Pupline task to send GIF data to the appropriate HITL job, plug our source of data into Pupline, and deploy; the job will automatically start filling with data. In addition, we’ve built a set of custom webhooks into Pupline for the HITL provider to call once the job has been completed, meaning the entire moderation flow can be written within a single application.
Because these jobs have a Human-in-the-loop component, they take a long time relative to entirely automated tasks – on the order of 10 minutes or longer. In order to not tie up resources, rather than wait on these tasks to complete, the Celery workers do not keep track of which GIFs are in transit or moderation — when a HITL job completes, a webhook is called which spawns a new task to further process the GIF.
Machine learning and computer vision

In addition to some contracted human assisted moderation, there are many tasks that we can trust solely to computers. Tasks like face and object detection, action and scene analysis, and automatically generating titles for GIFs, can all be entrusted to machine learning or other automated systems. Pupline exposes several pathways for this, running GIFs through both our internal systems, and through cloud providers such as Google Cloud Vision. These tools allow us to enrich our data about uploaded GIFs and help improve our search performance by exposing information about the content of the GIFs.
Because the tools we use for automated processing are fast, these tasks can run synchronously: we chain multiple automated tasks together, and the process can complete within seconds of upload.
What’s next?
As we continue to expand the number of tasks that Pupline executes, we hope to make it more flexible and add more sources of data. Currently, data is only input through REST calls to Django endpoints — eventually, we would like to provide GRPC endpoints and the ability to send input through a queue, allowing data from more sources without hurting application performance. In addition, as we improve our testing and monitoring, we hope to enable every GIPHY engineer to quickly and safely add new tasks with minimal oversight.
— Jacob Graff
Software Engineer, Services